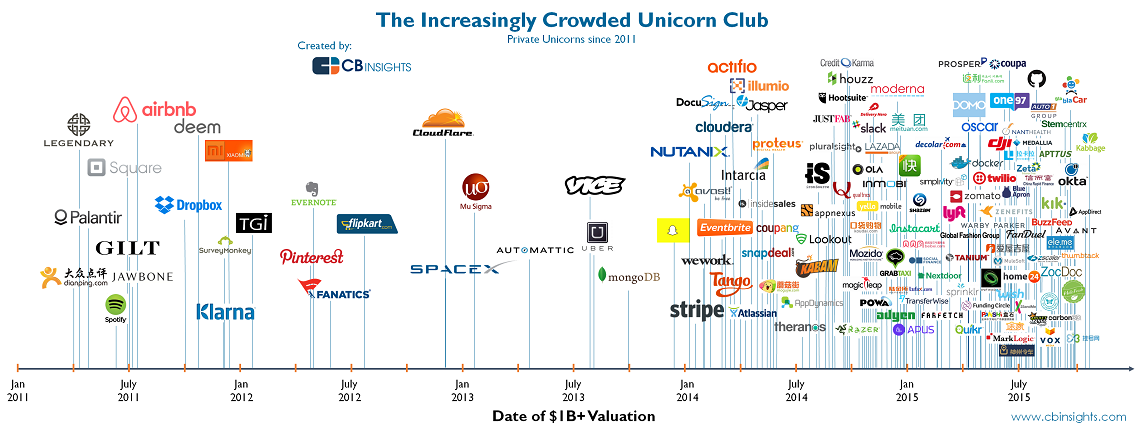
There have been visions of smart, communicating objects even before the global computer network was launched forty-five years ago. As the Internet has grown to link all signs of intelligence (i.e., software) around the world, a number of other terms associated with the idea and practice of connecting everything to everything have made their appearance, including machine-to-machine (M2M), Radio Frequency Identification (RFID), context-aware computing, wearables, ubiquitous computing, and the Web of Things. Here are a few milestones in the evolution of the mashing of the physical with the digital.
1932 Jay B. Nash writes in Spectatoritis: “Within our grasp is the leisure of the Greek citizen, made possible by our mechanical slaves, which far outnumber his twelve to fifteen per free man… As we step into a room, at the touch of a button a dozen light our way. Another slave sits twenty-four hours a day at our thermostat, regulating the heat of our home. Another sits night and day at our automatic refrigerator. They start our car; run our motors; shine our shoes; and cult our hair. They practically eliminate time and space by their very fleetness.”
January 13, 1946 The 2-Way Wrist Radio, worn as a wristwatch by Dick Tracy and members of the police force, makes its first appearance and becomes one of the comic strip’s most recognizable icons.
1949 The bar code is conceived when 27 year-old Norman Joseph Woodland draws four lines in the sand on a Miami beach. Woodland, who later became an IBM engineer, received (with Bernard Silver) the first patent for a linear bar code in 1952. More than twenty years later, another IBMer, George Laurer, was one of those primarily responsible for refining the idea for use by supermarkets.
1955 Edward O. Thorp conceives of the first wearable computer, a cigarette pack-sized analog device, used for the sole purpose of predicting roulette wheels. Developed further with the help of Claude Shannon, it was tested in Las Vegas in the summer of 1961, but its existence was revealed only in 1966.
October 4, 1960 Morton Heilig receives a patent for the first-ever head-mounted display.
1967 Hubert Upton invents an analog wearable computer with eyeglass-mounted display to aid in lip reading.
October 29, 1969 The first message is sent over the ARPANET, the predecessor of the Internet.
January 23, 1973 Mario Cardullo receives the first patent for a passive, read-write RFID tag.
June 26, 1974 A Universal Product Code (UPC) label is used to ring up purchases at a supermarket for the first time.
1977 CC Collins develops an aid to the blind, a five-pound wearable with a head-mounted camera that converted images into a tactile grid on a vest.
Early 1980s Members of the Carnegie-Mellon Computer Science department install micro-switches in the Coke vending machine and connect them to the PDP-10 departmental computer so they could see on their computer terminals how many bottles were present in the machine and whether they were cold or not.
1981 While still in high school, Steve Mann develops a backpack-mounted “wearable personal computer-imaging system and lighting kit.”
1990 Olivetti develops an active badge system, using infrared signals to communicate a person’s location.
September 1991 Xerox PARC’s Mark Weiser publishes “The Computer in the 21st Century” in Scientific American, using the terms “ubiquitous computing” and “embodied virtuality” to describe his vision of how “specialized elements of hardware and software, connected by wires, radio waves and infrared, will be so ubiquitous that no one will notice their presence.”
1993 MIT’s Thad Starner starts using a specially-rigged computer and heads-up display as a wearable.
1993 Columbia University’s Steven Feiner, Blair MacIntyre, and Dorée Seligmann develop KARMA–Knowledge-based Augmented Reality for Maintenance Assistance. KARMA overlaid wireframe schematics and maintenance instructions on top of whatever was being repaired.
1994 Xerox EuroPARC’s Mik Lamming and Mike Flynn demonstrate the Forget-Me-Not, a wearable device that communicates via wireless transmitters and records interactions with people and devices, storing the information in a database.
1994 Steve Mann develops a wearable wireless webcam, considered the first example of lifelogging.
September 1994 The term ‘context-aware’ is first used by B.N. Schilit and M.M. Theimer in “Disseminating active map information to mobile hosts,” Network, Vol. 8, Issue 5.
1995 Siemens sets up a dedicated department inside its mobile phones business unit to develop and launch a GSM data module called “M1” for machine-to-machine (M2M) industrial applications, enabling machines to communicate over wireless networks. The first M1 module was used for point of sale (POS) terminals, in vehicle telematics, remote monitoring and tracking and tracing applications.
December 1995 MIT’s Nicholas Negroponte and Neil Gershenfeld write in “Wearable Computing” in Wired: “For hardware and software to comfortably follow you around, they must merge into softwear… The difference in time between loony ideas and shipped products is shrinking so fast that it’s now, oh, about a week.”
October 13-14, 1997 Carnegie-Mellon, MIT, and Georgia Tech co-host the first IEEE International Symposium on Wearable Computers, in Cambridge, MA.
1999 The Auto-ID (for Automatic Identification) Center is established at MIT. Sanjay Sarma, David Brock and Kevin Ashton turned RFID into a networking technology by linking objects to the Internet through the RFID tag.
1999 Neil Gershenfeld writes in When Things Start to Think: “Beyond seeking to make computers ubiquitous, we should try to make them unobtrusive…. For all the coverage of the growth of the Internet and the World Wide Web, a far bigger change is coming as the number of things using the Net dwarf the number of people. The real promise of connecting computers is to free people, by embedding the means to solve problems in the things around us.”
January 1, 2001 David Brock, co-director of MIT’s Auto-ID Center, writes in a white paper titled “The Electronic Product Code (EPC): A Naming Scheme for Physical Objects”: “For over twenty-?ve years, the Universal Product Code (UPC or ‘bar code’) has helped streamline retail checkout and inventory processes… To take advantage of [the Internet’s] infrastructure, we propose a new object identi?cation scheme, the Electronic Product Code (EPC), which uniquely identi?es objects and facilitates tracking throughout the product life cycle.”
March 18, 2002 Chana Schoenberger and Bruce Upbin publish “The Internet of Things” in Forbes. They quote Kevin Ashton of MIT’s Auto-ID Center: “We need an internet for things, a standardized way for computers to understand the real world.”
April 2002 Jim Waldo writes in “Virtual Organizations, Pervasive Computing, and an Infrastructure for Networking at the Edge,” in the Journal of Information Systems Frontiers: “…the Internet is becoming the communication fabric for devices to talk to services, which in turn talk to other services. Humans are quickly becoming a minority on the Internet, and the majority stakeholders are computational entities that are interacting with other computational entities without human intervention.”
June 2002 Glover Ferguson, chief scientist for Accenture, writes in “Have Your Objects Call My Objects” in the Harvard Business Review: “It’s no exaggeration to say that a tiny tag may one day transform your own business. And that day may not be very far off.”
January 2003 Bernard Traversat et al. publish “Project JXTA-C: Enabling a Web of Things” in HICSS ’03 Proceedings of the 36th Annual Hawaii International Conference on System Sciences. They write: “The open-source Project JXTA was initiated a year ago to specify a standard set of protocols for ad hoc, pervasive, peer-to-peer computing as a foundation of the upcoming Web of Things.”
October 2003 Sean Dodson writes in the Guardian: ”Last month, a controversial network to connect many of the millions of tags that are already in the world (and the billions more on their way) was launched at the McCormick Place conference centre on the banks of Lake Michigan. Roughly 1,000 delegates from across the worlds of retail, technology and academia gathered for the launch of the electronic product code (EPC) network. Their aim was to replace the global barcode with a universal system that can provide a unique number for every object in the world. Some have already started calling this network ‘the internet of things’.”
August 2004 Science-fiction writer Bruce Sterling introduces the concept of “Spime” at SIGGRAPH, describing it as “a neologism for an imaginary object that is still speculative. A Spime also has a kind of person who makes it and uses it, and that kind of person is somebody called a ‘Wrangler.’ … The most important thing to know about Spimes is that they are precisely located in space and time. They have histories. They are recorded, tracked, inventoried, and always associated with a story… In the future, an object’s life begins on a graphics screen. It is born digital. Its design specs accompany it throughout its life. It is inseparable from that original digital blueprint, which rules the material world. This object is going to tell you – if you ask – everything that an expert would tell you about it. Because it WANTS you to become an expert.”
September 2004 G. Lawton writes in “Machine-to-machine technology gears up for growth” in Computer: “There are many more machines—defined as things with mechanical, electrical, or electronic properties—in the world than people. And a growing number of machines are networked… M2M is based on the idea that a machine has more value when it is networked and that the network becomes more valuable as more machines are connected.”
October 2004 Neil Gershenfeld, Raffi Krikorian and Danny Cohen write in “The Internet of Things” in Scientific American: “Giving everyday objects the ability to connect to a data network would have a range of benefits: making it easier for homeowners to configure their lights and switches, reducing the cost and complexity of building construction, assisting with home health care. Many alternative standards currently compete to do just that—a situation reminiscent of the early days of the Internet, when computers and networks came in multiple incompatible types.”
October 25, 2004 Robert Weisman writes in the Boston Globe: “The ultimate vision, hatched in university laboratories at MIT and Berkeley in the 1990s, is an ‘Internet of things’ linking tens of thousands of sensor mesh networks. They’ll monitor the cargo in shipping containers, the air ducts in hotels, the fish in refrigerated trucks, and the lighting and heating in homes and industrial plants. But the nascent sensor industry faces a number of obstacles, including the need for a networking standard that can encompass its diverse applications, competition from other wireless standards, security jitters over the transmitting of corporate data, and some of the same privacy concerns that have dogged other emerging technologies.”
2005 A team of faculty members at the Interaction Design Institute Ivrea (IDII) in Ivrea, Italy, develops Arduino, a cheap and easy-to-use single-board microcontroller, for their students to use in developing interactive projects. Adrian McEwen and Hakim Cassamally in Designing the Internet of Things: “Combined with an extension of the wiring software environment, it made a huge impact on the world of physical computing.”
November 2005 The International Telecommunications Union publishes the 7th in its series of reports on the Internet, titled “The Internet of Things.”
June 22, 2009 Kevin Ashton writes in “That ‘Internet of Things’ Thing” in RFID Journal: “I could be wrong, but I’m fairly sure the phrase ‘Internet of Things’ started life as the title of a presentation I made at Procter & Gamble (P&G) in 1999. Linking the new idea of RFID in P&G’s supply chain to the then-red-hot topic of the Internet was more than just a good way to get executive attention. It summed up an important insight—one that 10 years later, after the Internet of Things has become the title of everything from an article in Scientific American to the name of a European Union conference, is still often misunderstood.”
Thanks to Sanjay Sarma and Neil Gershenfeld for their comments on a draft of this timeline.
[Originally posted on Forbes.com]