
Looking for a good AI Prompt Generator to create your desired AI Image or Art online? Then, we have got you covered! You can now generate detailed AI prompts by simply providing short descriptions in AI Prompt Generators.

AI Images, texts, and art tools such as Midjourney, DALL-E 2, ChatGPT, and Stable Diffusion functions on Prompts provided by users. Without an effective prompt, you can’t get your desired AI image, artwork, or text generation.
AI Prompt Generators are tools that utilize Artificial Intelligence and machine learning algorithms to generate unique and high-quality prompts for AI Image, Art, and Text generation.
With the help of these prompt generators, users can generate excellent AI prompts within a few seconds based on their preferences and necessities. In this article, we are going to mention the 8 Best AI Prompt Generators that you can use to create the perfect prompt. So, let’s get started.
What is an AI Prompt Generator?
An AI Prompt Generator is a tool that utilizes natural language processing and machine learning algorithms to generate unique and detailed prompts for numerous AI tools such as Midjourney, ChatGPT, DALL-E 2, Stable Diffusion, and more.
These prompt-generating tools help users create detailed and high-quality prompts that can help them create stunning AI videos, images, Art, or Text outputs. Some of the most popular AI Prompt Generators are PromptoMania, PromptPerfect, PromptHeor, WebUtility, and more.
8 Best AI Prompt Generator to Try Right Now
1. AI Text Prompt Generator
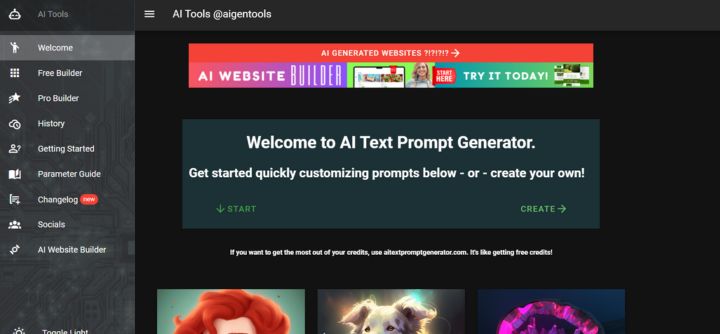
AI Text Prompt Generator is an excellent tool that can help you create amazing AI prompts for your images. The user-friendly interface makes it easy for users to access this platform including beginners.
To use this platform, users need to begin by entering a base prompt, where you need to define what kind of image you are looking for. After this, you need to choose a subject of your preference such as Animal, Character, Magic Artifacts, and more.
Next, you need to select an action of your choice such as Magic Actions, Sports, Crazy Action, and more. Now, you can test your prompt and check how well it works. Based on your preference you can add more patterns to get more effective results.
Key Features:
- This is a fast and reliable AI prompt-generating tool that can generate well-written prompts within a few seconds.
- It allows users to select their desired Subject and Action.
- Users can test out their prompt and further edit it to generate their desired results.
Pricing of AI Text Prompt Generator:
This tool contains a free plan. While there is also a paid plan available for lifetime access for $48 or $18/month containing ChatGPT prompts.
2. PromptoMania
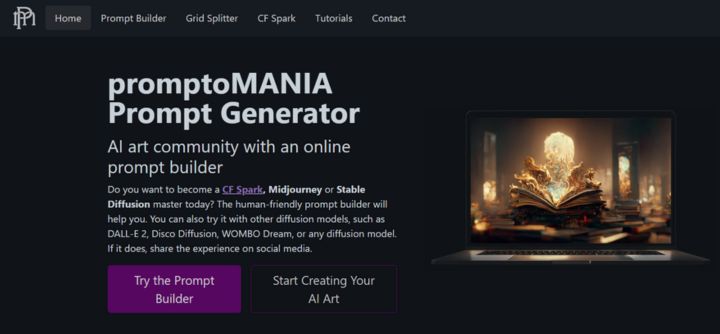
PromptoMania is an AI Image prompt generator that can create detailed prompts for almost any text-to-image diffusion model. With this tool, you can become a CF Spark, Midjourney, or Stable Diffusion expert today and generate high-quality AI Art prompts within a few seconds.
PromptoMania contains a user-friendly prompt builder that will help you develop the best AI prompts for your AI Art generation. Users can also try it with various diffusion models including WOMBO Dream, DALL-E 2, Disco Diffusion, and more.
Key Features:
- Users can generate various high-quality and detailed AI prompts using this tool.
- It contains a user-friendly interface that can be easily accessed by anyone.
- Supports a variety of diffusion models such as Disco Diffusion, DALL-E 2, WOMBO, etc.
Pricing of PromptoMania:
PromptoMania is a free AI Art Prompt generator.
3. PromptPerfect
PromptPerfect is one of the leading AI prompt-generating tools in the market. This prompt optimization tool can help enhance the overall quality of the large language model (LLM) and large model results.
To access PromptPerfect, users need to start by providing a short prompt describing what they are looking for and customizing the settings based on their preferences.
Users can adjust numerous settings in PromptPerfect such as the number of iterations to be optimized, Maximum prompt length, and Output quality.
The best part about this tool is that it supports a wide range of large language models such as ChatGPT, DALL-E, Midjourney, Stable Diffusion, and more. In general, users can access PromptPerfect for almost any model that utilizes language models for text generation or analysis.
Key Features:
- This prompt optimization tool helps generate high-quality AI prompts which can help enhance the quality and generate reliable responses to user’s input.
- PromptPerfect can help users generate excellent prompts for a variety of LLMs such as GPT-3, DALLE, Stable Diffusion, Midjourney, etc.
- In PromptPerfect, your prompts are your own and users have complete control to export their data to their local device or delete the data from the servers whenever they want. The server is regularly updated with the latest security protocols and patches to ensure the highest level of security.
Pricing of PromptPerfect:
PromptPerfect offers a free plan through which users receive 50 free credits once logged in to the website. 1 credit can be exchanged for 10 requests quota in Prompt-as-a-Service. PromptPerfect also offers premium plans through which users can purchase additional credits for prompt generation, which are as follows:
| Lite Plan | Standard Plan | Max Plan |
| $9.99/month | $39.99/month | $99.99/month |
| 200 credits~$0.05 per prompt | 1000 credits~$0.04 per prompt | 5000 credits~$0.02 per prompt |
4. WebUtility
WebUtility is another Impressive AI Image Prompt Generator that can help you generate unique and creative AI image results. WebUtility can generate unique prompts for a variety of AI Art AI-generating tools such as MidJourney, DALL-E 2, Stable Diffusion, Dream Studio, etc.
This is a perfect tool for designers, artists, developers, and more who want to explore the possibilities of image generation and transform their Imaginations into Images.
WebUtility provides users with numerous options for characters, themes, concepts, and much more through which users can explore their capabilities by pushing the boundaries and generating stand-out AI images.
Unlike other platforms, WebUtility encourages its users to experiment with different combinations of parameters to create unique prompts that will inspire users with their next AI image generation project.
This platform contains a “Random Prompt Generator” option through which users can generate an entirely random prompt, using a simple click. This helps provide completely unique and out-of-the-box prompts, which might help users gain inspiration for their next image generation.
Key Features:
- It supports numerous AI Art generators such as DALL-E 2, Dream Studio, Midjourney, and more.
- It contains a “Random Prompt Generator” through which users can create random and unique AI prompts.
- Provides a simple and easy-to-access interface.
Pricing of WebUtility:
WebUtility is a free AI prompt generator that can be accessed by anyone.
5. AI Art Prompt Generator
AI Art Prompt Generator is your personal AI Art Prompt Assistant tool that can create well-written prompts for stunning AI Art generation. This is a perfect tool for creators and artists who want to explore their imaginations and generate unique AI images.
This is an excellent tool, through which users can gain higher inspiration on exceptional artwork pieces. The best part about this tool is that it contains a user-friendly interface that can be easily accessed by anyone including beginners.
To use this tool, users need to simply enter a short description of what kind of AI Art they are looking for and click on “Get Ideas.” In a few seconds, this AI prompt generator will create various AI prompts based on your entered description.
Users can simply copy and paste the generated AI Prompts to various AI models such as Midjourney, Stable Diffusion, or DALL-E 2 and create their desired AI artwork.
Key Features:
- This is a great platform for beginners as it contains a user-friendly interface.
- It can generate a wide range of prompt ideas for users based on their preferences and necessity.
- Allow users to explore their imaginations and create unique AI images.
Pricing of AI Art Prompt Generator:
This is a free AI Art prompt art-generating tool that can be accessed by anyone without the need to sign up.
6. PromptHero
PromptHero is an impressive AI Prompt AI-generating tool for Artificial Intelligence and Prompt Engineering. This tool can help you generate excellent AI prompts for some of the best AI tools such as Midjourney, Stable Diffusion, ChatGPT, and more.
With this tool, users can search for a variety of AI prompts and get a million ideas and suggestions that can inspire their next prompt engineering session. It contains a huge library that includes numerous art styles.
Users can click on any images available on PromptHero and check out the entire prompt available. It even contains a community where users can share their work and gain inspiration from other users’ creations.
Key Features:
- Supports Midjourney, ChatGPT, Stable Diffusion, and more AI models.
- Contains a large library of Art styles available such as Portraits, Anime, Fashion, Character Design, and more.
- It contains an active community where users share their tricks, showcase their work, hone their skills, and generate eye-catching images.
Pricing of PromptHero:
PromptHero Pro available for $9/month provides image generation credits, a professional prompting portfolio with a stunning profile & access to unique features.
7. Prompts.chat

This AI prompt-generating tool is specially built for ChatGPT work. Prompts.chat contains a massive range of prompts divided by numerous categories such as Act as a Linux Terminal, Act as an English Pronunciation Helper, Act as a Travel Guide, Act as a Plagiarism Checker, and more.
Users can simply select any category based on their preference and copy and paste the prompt on ChatGPT. In this platform, you will witness various types of prompts asking ChatGPT to “roleplay” instead of generating a certain type of content.
For example, instead of giving you prompts such as “check if my content has any plagiarism” it will provide a prompt that says, “I want to Act as a Plagiarism Checker.” Overall, it is a great prompt-generating platform for ChatGPT with a wide range of category options available.
Key Features:
- Users can easily edit and copy the prompts on this site based on their preferences and needs.
- It contains a wide range of Prompt options supporting various categories.
- This tool is specially built for text generation for the ChatGPT platform.
Pricing of Prompts.chat:
Prompts.chat is a free-to-use AI tool through which anyone can copy and paste the prompts to ChatGPT to get their desired results.
8. PromptBase
PromptBase is a marketplace where users can purchase and sell high-quality prompts to produce stunning outputs by saving money on API costs. This platform contains excellent AI prompts for various AI models such as Midjourney, DALL-E, Stable Diffusion, and more.
The best part about this tool is that it provides excellent prompts for users based on their requirements.
There is a wide range of Prompt options available on PromptBase such as Logo prompts, Cartoon, Graphic and design, Marketing and business, Art and illustrations, and more.
Users can instantly hire a prompt engineer which can help them craft excellent text prompts required for an AI model to produce consistent outputs. Overall, this is a great prompt-generating tool for high-quality AI prompts.
Key Features:
- Provides a wide range of prompt options for numerous tasks and domains such as AI Art, Text, Images, etc.
- Allow users to sell their prompts online and connect them with an audience struggling with prompt generation.
- Supports various AI models such as DALL·E, Midjourney, Stable Diffusion, and GPT-3.
Pricing of PromptBase:
The starting price of AI prompts on this tool is available for $2.99 one-time-payment.
How an AI Prompt Generator Works?
An AI Prompt Generator leverages the advanced technology of AI, machine learning algorithms, and natural language processing techniques to identify the language pattern to create a wide range of writing patterns.
Based on users’ requirements and preferences it generates unique prompts relevant to the context.
Conclusion
AI Prompt Generators have made it easier for users to generate the perfect Prompt to achieve their desired results. However, it’s essential to select a good AI prompt generator to achieve the best results.
Above we have listed down some of the best AI Prompt Generator free and paid that can help you create the best AI prompts for your AI Images, Artworks, and Texts.
We hope this article has helped you in selecting an AI Prompt generator suitable for your requirements and needs.









































